In this blog post, I will outline my favorite user-focused approach to accessibility testing, show how this can be applied in your Cypress tests, and explain why Cypress Component Tests may be the best place to do this kind of testing.
Accessibility can be a complicated and intimidating topic. Often when we talk about it, we think in terms of checklists, Web Content Accessibility Guidelines (WCAG) criteria, and legal requirements. But at its core, it isn’t really about those things: it’s about communicating what’s going on in our applications to disabled users and making sure the experience is complete for them. Putting the user first when developing and testing features is critical to achieving day-to-day, functional accessibility.
Background
Long before I worked at Cypress, I spent about eight years working with disabled adults in one form or another, often in the area of supported employment, helping people to learn new tools and technologies as they came along. I’ve sat with a lot of people who’ve struggled to complete a task or understand an interface due to accessibility problems.
Our work as front-end developers has a huge impact on the independence of disabled users when using software. Simple choices, like what HTML we use, can have big implications for some users being able to complete tasks on their own, or having to ask for help. That’s a responsibility developers don’t always realize that they have, which means accessibility can be overlooked in development and testing. We often pay for this by compensating and working around the lack of accessibility, in various ways, without even noticing that we have created extra work for ourselves.
In this post I’ll describe how accessibility works in the browser and how to test for it in ways that go beyond automated audits and technical criteria. We do this by putting the user first in our thinking, testing from the user’s perspective, and keeping a keen focus on validating our code through what it communicates to the user.
This communication from developer to user, encoded through our HTML, is what helps disabled users perceive content and perform actions in our websites and applications in a way that works for them. On the other hand, our HTML choices can also create barriers and reduce independence, and we’ll talk about that as well.
Contents
- How web accessibility works
- How user-focused testing helps
- Comparison of three different methods of locating a link element
- Strengths of the user-focused approach
- Where to write tests like this
- Combining testing types
- Conclusion
How web accessibility works
When thinking about accessibility it can be easiest to think about assistive technology (AT) like screen readers, braille displays, sip-and-puff devices, and even plain old keyboards.
Tools like this provide information about what content is on the page at a given time, what actions are available, and they provide a way to interact with actionable elements. These tools also react to, and communicate, the state of your application. AT provides these things in a fashion that meets the specific needs of particular users, who can choose the assistive technology that best supports them. Tools like this are all built on top of a browser feature known as the Accessibility Tree, which browsers create based on the HTML in our web pages. This tree provides a universal API that other tools can tap into to create customized accessible experiences.
The Accessibility Tree is similar to the DOM tree, which is a concept we might be more familiar with as developers. Just like the DOM, it is a nested structure that browsers build from our HTML. Unlike the DOM however, the Accessibility Tree does not have HTML elements as nodes – instead the nodes, and the tree as a whole, reflect specific element roles and hierarchies found in the DOM.
Assistive technologies can provide all kinds of useful tooling to users, based on the nature and structure of the content that is present on the DOM and translated into the Accessibility Tree. Here are some features of a screen reader, which may be used by a blind person to explore and interact with a document:
- Announce all of the headings in the document in order, following the nested structure of heading elements to help quickly understand the page structure
- Announce all of the links in the page to understand how this page connects to other content
- Announce the
alttext associated with an image - Describe the label of a button element or form field, as well as the state - for example, read back the text that is currently entered in a field
Tools like this are capable of providing access to the full content and functionality of a web page, as long as the page is using semantic HTML correctly and following some basic conventions.
The most important thing to know about the Accessibility Tree and the tools that depend on it is this: it’s a classic “garbage in, garbage out” situation. The specific HTML elements used matter because they reflect the nature of the content. This is also where thoughtful, intentional testing can help the most.
Here’s an example: relationships like headings and subheadings are often obvious to sighted users due to the visual style of the page. This need to be expressed in correctly nested h* elements like <h1>, <h2>, etc. in order to be perceivable when the document is described by a screen reader. The enables “skimming” since a user can listen to just the headings of a page to understand what it contains.
Similarly, a feature like “announce all the links on a page” only works if certain conditions are met:
- Links must be real anchor elements, looking something like this
<a href="/home">Home</a> - Links must have unique names describing where they go - hearing “click here” or “learn more” announced 15 times tells the user nothing about where they can go from this page
That’s a short list, but in reality, it is common to see non-link elements that behave as links that work only for sight mouse-users, and are not exposed to screen reader or keyboard users. A div with a click handler that modifies location.href with JavaScript is not a link, for example. Not only will the element not be announced by a screen reader as a link, it also will not get the default correct keyboard behavior that comes with an anchor element, or the ability to open the link in a new tab.
If we use a real anchor element instead of a div, we will avoid needlessly recreating browser behavior with JavaScript, and we’ll have scored a win for disabled users who depend on semantic HTML. We can also have a fast, easy test to know if our link is correct and has the accessibility features we need:
cy.contains('a','Home').should('have.attr', 'href', '/home')Since all of the accessibility behavior we expect from a link is handled by the browser, and by the third-party assistive technology, we don’t actually need to test all that behavior for every link in our application. If we do, we are testing the browser itself, not our own code.
The browser makes a link focusable with a keyboard, the browser exposes the label and the destination to screen readers, and the browser navigates to the destination when the user presses Enter while the link has focus. As long as we have given the browser a real link, everything downstream "just works".
We’ll talk more about this kind of test in the next section.
How user-focused testing helps
There are many tools (such as cypress-axe) that can provide accessibility reports and offer suggestions to repair common accessibility errors. This post is not about that kind of testing, though it has an important place in an overall process, and can catch a large number of errors.
Automated, broad-stroke accessibility checks can never tell you whether the communication encoded in your HTML is correctly matching the nature and structure of your content. That’s something only humans can tell.
Testing our apps and components through “what they communicate to a user” is an excellent way to ask the right questions about accessibility early in the development lifecycle and correct issues quickly and easily. When we write a spec file, we are specifying the expected output of our application in response to various inputs. Web applications are complicated, expensive machines that produce HTML and send it to users. As we’ve discussed, the HTML makes a big difference to some users, so we should include it in our specs in a thoughtful, intentional way.
Here are some examples based on testing a link.
Locating a link using name, element selector, and [data-cy]
To be accessible, every interactive control on a page should have a label (technically, an accessible name). When we locate an interactive element for a test, we should be able to do so using something like cy.contains('a', 'Home'). This does a couple of things. First, it only matches a real link element, and second it makes sure that the element contains the expected text. This would not be ideal if there are multiple “Home” links on a page. At that point, we could introduce a data-cy or data-test attribute to our code to make sure we target the correct link. A full example might be:
cy.contains('a[data-cy=header-home-icon]', 'Home')
.should('be.visible')
.and('have.attr', 'href', '/home')This would find a link that has the name “Home”, confirm it is visible and that it has the expected href value. Visually the link might be represented by an icon in the header, but in our test we know that there is supposed to be a plain English label for every interactive element, so we look for that.
Locating a link using name and expected location in the accessibility tree
Even in the case above, where there might be multiple “Home” links, we might rewrite without the data-cy attribute and still be specific enough:
cy.contains('header nav a', 'Home')This would assert the important parts of the Accessibility Tree as it relates to finding that same link:
header nav adescribes the expected structure, we are locating an anchor element inside a nav element in the header, and we want the test to fail if this is not found.- The lack of a direct child combinators (
>) and container elements in the CSS selector means other elements can be added or removed in between his structure without breaking our test - And finally,
Homeidentifies the content itself, the name of the link.
This approach agrees heavily with the Testing Library Guiding Principles. cypress-testing-library is one of the first things I install in a new Cypress project, because of its excellent locators like findByLabelText for form fields. Testing Library also has findByRole locators, and while I use those occasionally, I prefer cy.contains(element, text) for buttons and links especially, because I want my test to specify the real HTML elements that should be used by the application, and only have the application reinvent the wheel with ARIA roles if there’s some really good reason.
Locating a link using CSS classes, element selectors and IDs
Let’s look at another way to locate a “Home” link. This is one I would consider to be a bad practice:
cy.get('div.header > div.main-nav > span.#home-container > a')This kind of thing may work, but remember: this is a spec file. Is it important to our users that this specific set of nested DOM elements exist in this exact order? When a test like this fails due to DOM changes in the application over time, is that test telling us the application is broken, or just that the DOM has changed?
I’d consider this kind of locator to be one that over-specifies the HTML output of the app. Even though this finds the same element as the other options above, we’ve made our test care about things that don’t matter to a user, and we’ve left out some things that do matter, like the name of the link. So the test is less effective, and more brittle.
When all of our tests are like this, we begin to feel that testing is pointless, that there are lots of false failures, and we create complex systems to manage and update element locators since developers are always “breaking” them when implementing design changes.
Strengths of the user-focused approach
Let’s consider this locator one more time:
cy.contains('header nav a', 'Home')This will only fail to locate the element if something important has changed:
- If the name of the link changes, I want a test to fail, because that matters to users.
- If the main navigation of the website doesn’t have a link to the homepage, that’s probably also something worth failing the test over, so the
header nav aselector seems fine too.
Since we are not specifying any CSS classes, direct parent-child element relationships, or element IDs, this locator will be resilient to design changes that move HTML around and change the nesting for layout reasons. This solves a major source of “brittle” UI tests - tests that fail when trivial HTML changes are made even though everything still works.
By focusing on what the element means to the user, we have created a more readable and stable test that only specifies what is really necessary to be considered “correct behavior”.
Where to write tests like this
While my favorite option is just always to test like this, I think the most important place to make these kinds of user-focused assertions is in component tests.
There are several reasons for this:
The developer working on the component is likely to have the component test open.
This developer is making decisions about the HTML and driving the accessibility of the component anyway, so encoding that in the tests as well is a great way to keep everything aligned and catch accessibility regressions in the future.
Component tests are the easiest place to add these assertions since the developer has the context as they write the component
A component is usually rendered in isolation, so there is only one instance at a time. We won’t have any interference from other components on the page that might have similar elements, so we don’t need to worry about sorting them out with data-attributes.
Component tests control more variables
Compared to end-to-end tests, we usually have much more control over the text content that appears in a component test. We can have higher expectations that this content is safe to depend on in a test, and not coming from an external source that could be modified causing the test to fail.
Component tests often cover functional pieces of UI with text that is a core part of correct functionality
For example, form fields and labels must be correctly associated so that the user-facing description of the form matches the underlying data schema. A component test can specify that “typing hello into a field with label ‘First Name’ populates the firstName property of an object sent in a POST request when a form is submitted”. If users do not know which field they are typing into because the labels get moved around or can’t be associated correctly when the form is read aloud, they are not going to be successful filling out the form correctly.
Browser-based component tests let you see the Accessibility Tree in real time
Here is an example of using the accessibility tree in Chrome’s Dev Tools to highlight a button with no text. It shows us with a popup which button we have hovered over in the tree. This can help us realize that there is no text for the button, and add some invisible text that we can then use in our tests. This improves the test as well as the screen reader experience.
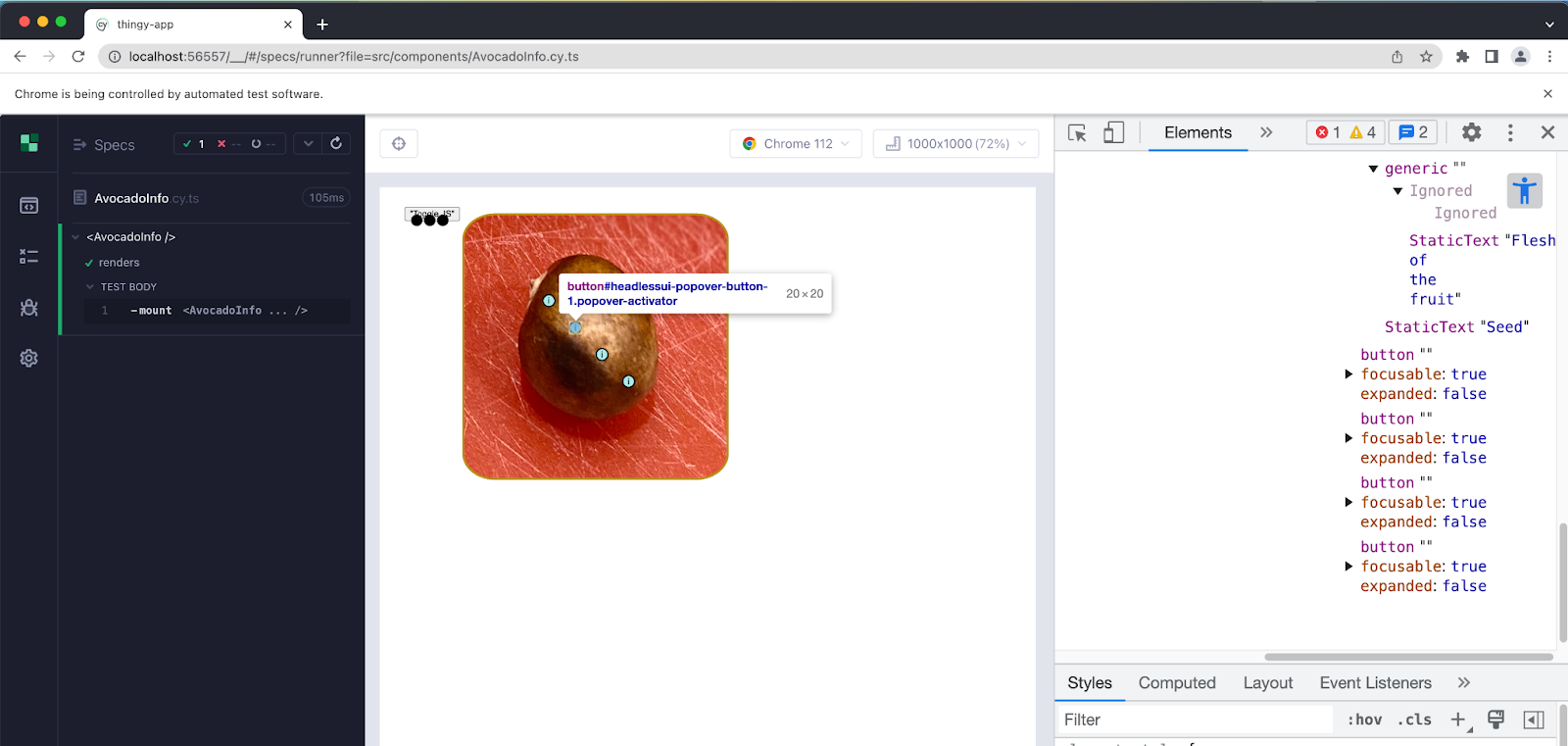
You can learn more about the accessibility tree in Chrome on Google’s web.dev guide.
While you can test many of these exact things from end-to-end tests, component tests provide the fastest feedback to developers because they usually run much more quickly than end-to-end tests and are more focused. As mentioned above, it’s natural to have this kind of test open when working on a component, so any regressions or bugs can be noticed within seconds of making a change.
When thinking about accessibility and component testing, I see it this way: each component renders a small piece of the overall DOM in a page, and so each component is responsible for communicating one small part of the Accessibility Tree. Testing that at the component level helps reduce repetition in end-to-end tests, which can safely use other means like data-* attributes to create stable long term locators when needed.
If desired, locators can even be shared between component and end-to-end tests through custom commands or reusable functions, since they are written in the same Cypress syntax.
Combining testing types
Of course, there will always be some accessibility concerns that make sense to test at the end-to-end level. Components that are individually accessible can still be combined in inaccessible ways. So it makes sense to consider accessibility when testing all the way up the component tree, from utility components like Button and Link, through components with multiple children like a Form or a Menu, and on up to to whole pages in end-to-end tests.
The key thing is that we don’t need to repeat assertions across multiple levels of this tree. If the component tests are written to assert the aspects of accessibility that each component manages, the end-to-end tests can be a lot lighter, and focus on user flows across pages, rather than deeply checking the DOM for correctness in places where coverage already exists through faster-running component tests.
Since end-to-end tests are sometimes written by entirely separate teams than component tests, this can help prevent rework and create something of a safety net for testing important aspects of the HTML output of our applications that might not always be clear to people writing tests focused on high-level user journeys.
Learn more about combining component and end-to-end tests in our blog post, What Component Testing Means for Developers.
Conclusion
Accessibility is all about clear communication of the nature and structure of our content. This simple goal gives us a lens to look at the work of developing and testing applications that prioritizes the users. This process even has benefits in working with designers and product folks developing requirements, because we are constantly asking: What is this feature?
Designs encode meaning and information hierarchy through the sizing, spacing, and organization of elements. It’s up to developers to understand that meaning and create the correct HTML output of our software to allow assistive technologies to express the nature and structure of what’s on the page. When we write the code, we must think about creating independence and autonomy for disabled users. When we write tests, we must think about this important responsibility of the code. Our tests should hold the application the same way users will - through meaningful, labeled elements - at least once.
All of the accessibility auditing tools and automated reports work very effectively for what they do. But they work best on top of a core experience that is already trying to meet the needs of users. They can tell you if a button is missing a label, but they can’t tell you that your clickable div should be a button.
Next steps
- Join us for a live demo using the Accessibility Tree in Chrome to improve component tests and fix bugs on June 27 as part of our community event, Getting Started with Component Testing
- Ahead of that, if you’d like a deeper dive into testing this way in Cypress and accessibility in general, you can check out this talk from Stir Trek in Columbus, OH on May 5, 2023 called Maintaining Accessibility in Complicated Components, where I look at more advanced situations than I could cover in this blog post.
- To learn how a blind user actually navigates with a screen reader, check out Léonie Watson’s Smashing Magazine webinar, How A Screen Reader User Surfs The Web.
- To learn how to use Axe with Cypress, see Marie Drake’s talk How to Perform Accessibility Testing with Cypress. This will help catch errors in semantic HTML, ARIA roles, and text contrast and offer suggestions for correcting them.
Happy Testing!